高性能可视化架构:一个交互式实时数据引擎的架构设计
在分析 SecDB、Athena、Quartz 几个实时金融与风险分析平台的时候,发现了 Perspective —— 一个 FinTech 开源基金会 FinOS 旗下开源的交互式分析和可视化组件库,由摩根大通(J.P. Morgan Chase)公司开源出去的流式数据可视化组件库。所以,从某种意义上来说也是《金融 Python 即服务:业务自助的数据服务模式》 的后续展开,也可以算是低延迟架构的后续探索。
起初,我只是对其中使用的 ExprTk 感兴趣,后来发现这个库不简单:使用了 C++、Rust、Python、JavaScript、TypeScript 等语言。混合语言的项目都特别好玩,于是乎,我便开始探索它了。而我原先感兴趣的 x <= 'abc123' and (y in 'AString') or ('1x2y3z' != z) 的解析与实现,也就先放在一边了。
开始之前,先复制一下官方的介绍:
Perspective 是一个交互式分析和数据可视化组件,特别适合大型数据集或流数据。可以 使用它来创建用户可配置的报告、仪表板、Notebook 和应用程序,然后在浏览器中独立部署,或与 Python 和/或 Jupyterlab 协同部署。
简单来说,就是可以提供实时图形渲染,并支持 Jupyter 集成。如果是 Jupyter 的集成,那么从某种来说,它是一种金融工作台,类似于先前定义的架构工作台。
PS:写这样的工具太过复杂了,所以先写篇文章记录一下,等未来有空的时候,再写一个。
高性能可视化架构:Perspective 架构分析
初步绘制的 Perspective 架构图如下所示:
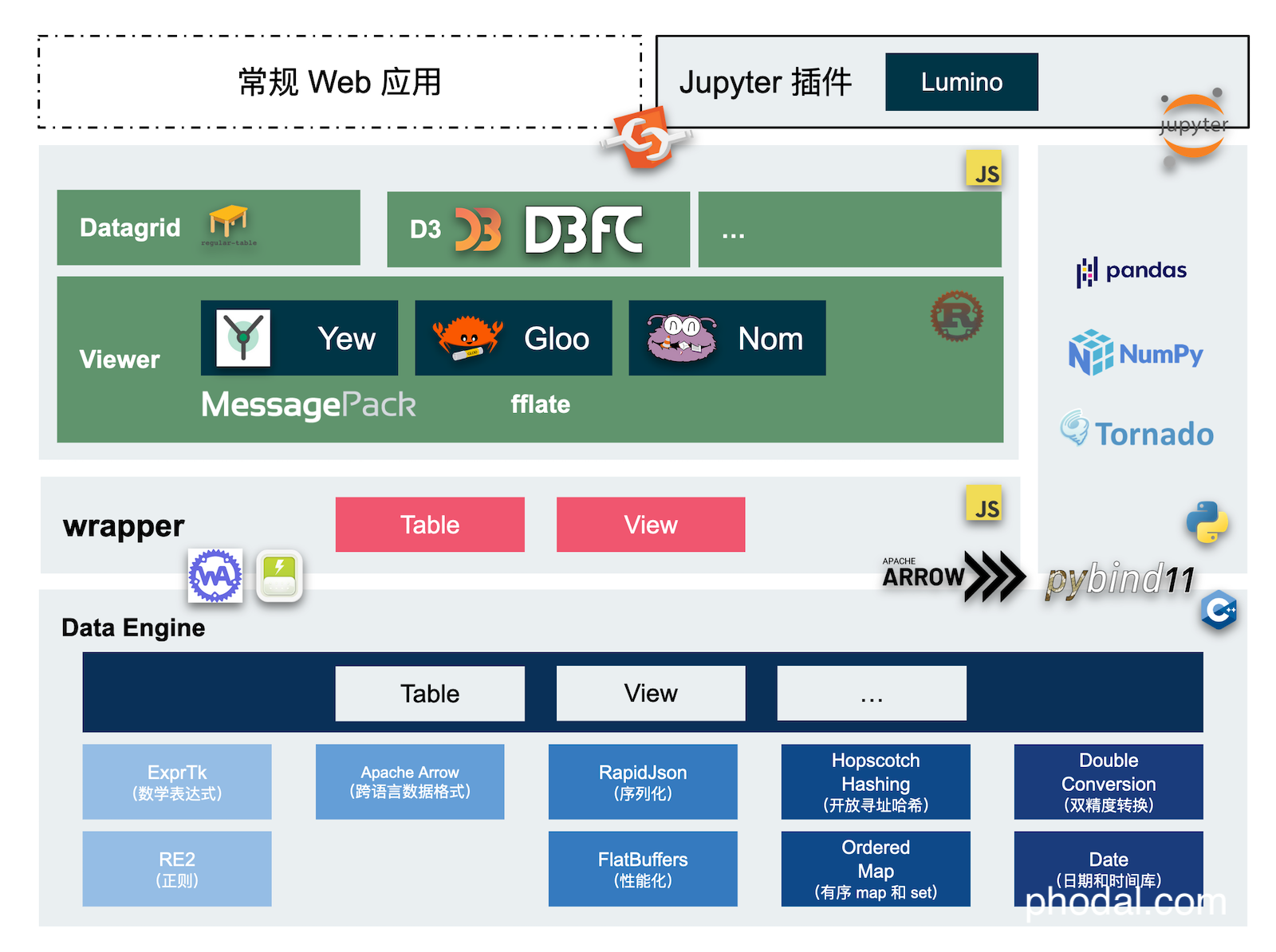
在 JavaScript 侧,系统可以分为三层:
- 数据引擎。使用 C++ 与一系列的数据结构库等,进行封装,并提供数据操作 API。通过 Emscripten 构建和封装,以提供 WASM 接口。
- wrapper 层。提供对于数据引擎的再次封装,以使 API 更符合日常的编程习惯,诸如于 table、view 等,还提供
worker、websocket等封装。 - UI 组件。viewer 分为 d3fc、datagrid、openlayers 等不同的组件,大部分使用纯 Rust 编写,提供 Web Component API 等。
在 Python 侧,除了相同的 UI 部分,还需要构建 Jupyter 插件:
- 数据引擎。结合 pybind11 来提供 FFI (Foreign Function Interface,外部函数接口)能力。
- wrapper 层。结合了 Python 数据科学生态中的 Pandas、Numpy 等工具,来进行数据转换。
- UI 层。结合 Lumino 对 UI 组件进行封装。
其中,比较有意思的是 Apache Arrow,提供了跨语言的数据支持。
密集计算下沉:C++ 与 WASM 应对挑战
对于将密集型计算下沉到 WASM 部分,相信大家都比较熟悉了。对于常规的 WASM 使用来说,需要平衡开发效率和运行效率,FFI 在调用的时候也存在性能损失。也因此,一种比较理想的方式是将数据操作,全部委托给 C++ 部分去实现。
如上面的架构图所示,Perspective 的计算部分,主要是 Table 对象实现的,它是 Perspective 中的基本数据容器。 Table 是有类型的 —— 它们有一组不可变的列名,每个都有一个已知的类型。每当有对数据的处理时,都会通过 WASM 来处理。过滤与计算,在这里也是一个非常有意思的问题,即上面说到的 ExptTk,便是用来做这部分计算用的。
值得注意的是,Perspective 之所以采用 C++ 来构建 WebAssembly 的方式,大概率是因为原有的一部分基础设施是基于 C++ 的。与此同时,原先采用的是 C++ 的 UI,以提供更好的性能。不过,Perspective 提供的 WASM 包,大概有 40M 左右,在初始化的时候相对慢了一点。
可是,又为什么是 Table 呢?这就得从 Apache Arrow 提供的能力说起。
无序列化与内存分析:Apache Arrow
对于序列化的性能优化,相信大家都比较熟悉了。通常来说一次数据传输操作包括:
- 以某种格式序列化数据
- 通过网络连接发送序列化数据
- 在接收端反序列化数据
于是乎,在很多系统中(如 ArchGuard),序列化就是系统的瓶颈。既然序列化会带来问题,那么就不应该有序列化。于是乎,我们就可以在上面的架构图中,看到两个工具:
- Apache Arrow。一个直接针对数据分析需求的数据层,提供分析所需的数据类型的综合集合。除了语言无关的标准化列式存储格式之外,它还包含三个特性:零拷贝共享内存和基于 RPC 的数据移动、读取和写入文件格式(如 CSV、Apache ORC 和 Apache Parquet)、内存分析和查询处理。
- FlatBuffers。同样的,无需解析/解包即可访问序列化数据。
不过呢,FlatBuffers 只是 Arrow 用来序列化实现 Arrow 二进制 IPC 协议所需的模式和其他元数据。随后,我们就可以使用 Table 来调用 Arrow 的 API 来进行计算。
Apache Arrow 的相关介绍可以见官方文档:https://arrow.apache.org/
灵活的前端组件:无框架与渲染机制优化
简单来说,只要是以下的两个特点:
- 无框架。对于一个以渲染为主的项目来说,Perspective 不采用任何框架。从某种意义上来说,更小的包大小,也带来了更好的性能。除此,作为一个纯粹的 web components 组件,它可以非常容易与几大主流框架结合到一起。
- 虚拟渲染的 Table。在 Table 显示上, Perspective 采用的是 JMPC 的 regular-table,同样也是 Web Components 组件,可以直接引入项目使用。并且支持虚拟渲染,即仅显示可视区域的数据,减少 DOM 节点以带来更好的性能。
对于 Web Component 和 Custom Element 部分,相信大家都比较熟悉了。它们使用起来和正常的 HTML 区别不大,如下是一个不同 UI 组件之间的关系示例:
<perspective-workspace>
<perspective-viewer>
<perspective-viewer-datagrid>
<regular-table />
</perspective-viewer-datagrid>
<perspective-viewer-datagrid-toolbar />
</perspective-viewer>
<perspective-viewer ... />
</perspective-workspace>每一个组件分别在不同的工程中,倒是挺 componentless 的。一旦数据发生变化的时候,就会从 viewer 侧,调用 update_and_render 从而更新 UI 部分的 render。
其它
参考材料:
- 《Apache Arrow 和 Java:大数据传输快如闪电》
- 《Perspective.js》官网
或许您还需要下面的文章:
围观我的Github Idea墙, 也许,你会遇到心仪的项目
- 设计流动摩擦:AI 原生团队的核心能力
- Piece:将 Coding Agent 的局部构建反馈提速 10x
- 验证工程:从 Vibe 硬件编程 Loop 到自迭代验证
- 长程验证:AI Agent 长任务的收敛机制
- 从复杂编辑器到 Agent 工作台:Office 的 Cursor 时刻
- 注意力 Harness:多 Agent 时代如何守住人的注意力
- Agent 应该如何解决繁杂任务:从 /goal 到长时间运行
- 任务自适应 Harness:从 Trace 到多 Coding Agent 的协作记忆
- 从写清 Spec 到看懂功能:在 Session 历史中使用 Routa 重建需求全景
- Routa 桌面版发布:内建 Harness 工程的 AI Coding 研发协作工作台
 Engineer, Consultant, Writer, Designer
Engineer, Consultant, Writer, Designer
ThoughtWorks 技术专家
工程师 / 咨询师 / 作家 / 设计学徒
开源深度爱好者
出版有《前端架构:从入门到微前端》、《自己动手设计物联网》、《全栈应用开发:精益实践》
联系我: h@phodal.com
微信公众号: 最新技术分享

- opensuse (10)
- django (41)
- arduino (10)
- thoughtworks (18)
- centos (9)
- nginx (18)
- java (10)
- SEO (9)
- iot (47)
- iot system (12)
- RESTful (23)
- refactor (17)
- python (47)
- mezzanine (15)
- test (11)
- design (16)
- linux (14)
- tdd (12)
- ruby (14)
- github (24)
- git (10)
- javascript (52)
- android (36)
- jquery (18)
- rework (13)
- markdown (10)
- nodejs (24)
- google (8)
- code (9)
- macos (9)
- node (11)
- think (8)
- beageek (8)
- underscore (14)
- ux (8)
- microservices (10)
- rethink (9)
- architecture (37)
- backbone (19)
- mustache (9)
- requirejs (11)
- CoAP (21)
- aws (10)
- dsl (9)
- ionic (25)
- Cordova (21)
- angular (16)
- react (14)
- ddd (9)
- summary (9)
- growth (10)
- frontend (14)
- react native (8)
- serverless (32)
- rust (9)
- llm (8)