金融 Python 即服务:业务自助的数据服务模式
最近,在研究国外的金融科技公司,他们如何构建他们的平台战略?机缘巧合之间,刚好看到一篇关于Bank Python 相关的文章《An oral history of Bank Python》。在这篇文章里,介绍了 Bank Python 的四种基础构建块:
- Barbara, the great key value store
- Dagger, a directed, acyclic graph of financial instruments
- Walpole, a bank-wide job runner
- MnTable, the ubiquitous table library
而围绕于这四个构建块创建的其中一类系统,则构建成了「金融 Python 即服务」的平台模式,即让金融从业人员能实现自助式的数据分析与处理。为此,我想编写一篇文章来介绍一下这种模式,方便于未来查阅。
问题
如何提供一种快速的大数据分析模式,以供金融从业者使用?
对于这个现代化的分析工具来说,它需要:
- 融合银行内部的风险管理等一系列特色的金融服务。
- 提供自助式的基础设施,以实现数据自助。
- 实时的海量事件数据处理机制,以实时响应市场的变化。
- 提供一种易于学习语言作为接口,以粘合内部的一系列服务。
只是呢,与通常的数据服务不一样的事,传统的分析模式,可能由开发人员导出报表进行分析,又或者是由拖拉拽的方式(低代码)来让业务人员操作。现代化的分析模式,则是围绕于 DSL 来构建数据自助服务。
解决方案
在参考了国外主流的一些金融科技公司的模式,以及他们背后的 Bank Python,也有诸如高盛一类 Bank Slang 的机制。基于他们的一些经验,以及系统现代化的趋势,便提炼了「金融 Python 即服务」模式 —— 让业务人员能自助对金融数据分析,以及快速扩展的分析能力,即实现数据自助服务。
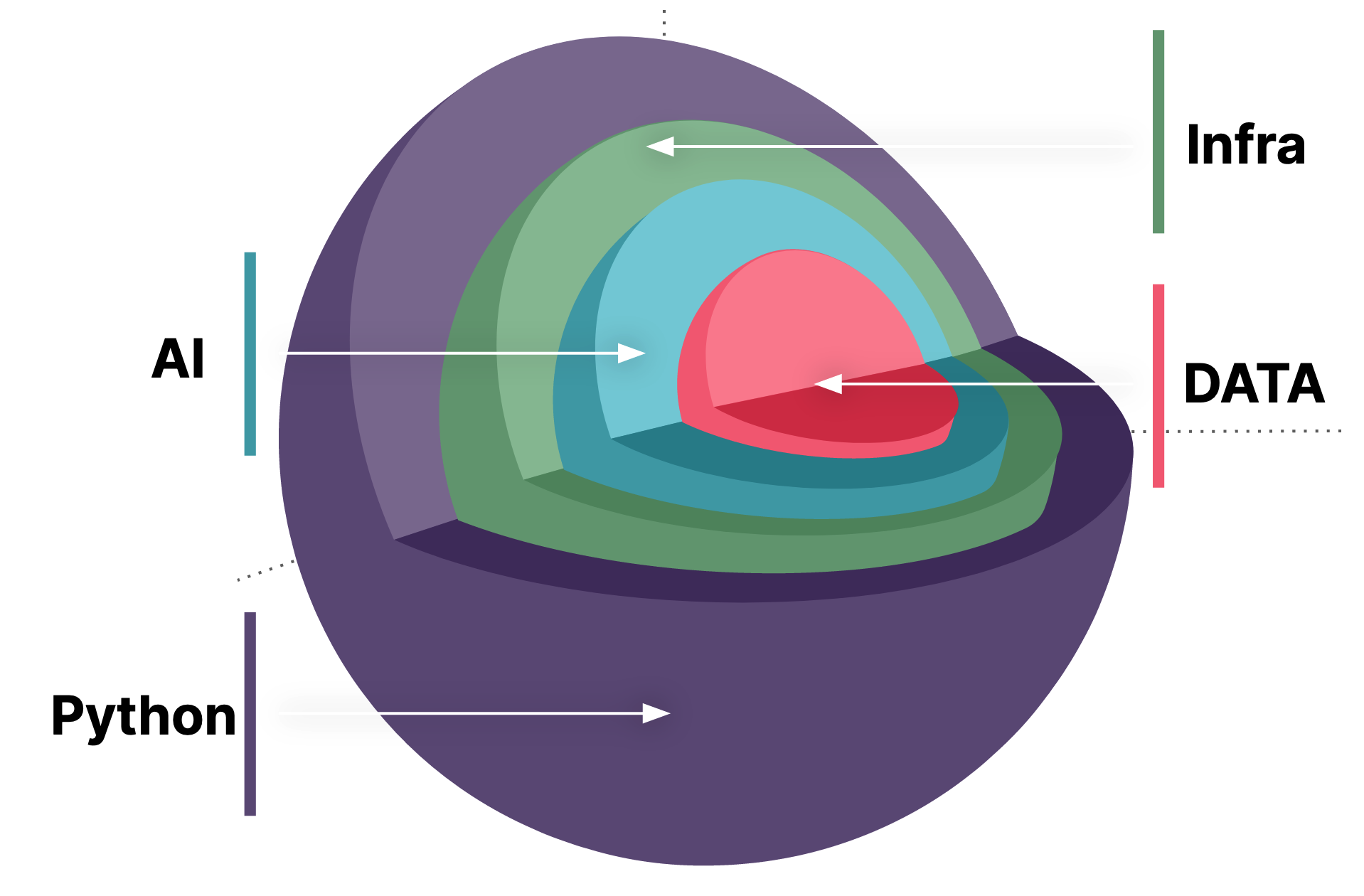
在这个机制下,便是业务人员编写 Python 代码来完成数据自助服务,查询、交互、分析、可视化等。而为了支撑业务人员使用 Python,又对公司的人才策略提出了挑战,金融公司所需要的是金融工程人才,才能将创新发挥到极致。当然了,这个解决方案并不简单,需要融合三个领域的专家:金融工程、数学科学、人工智能,除此,我们还需要关注于如何构建快速交付的基础设施。
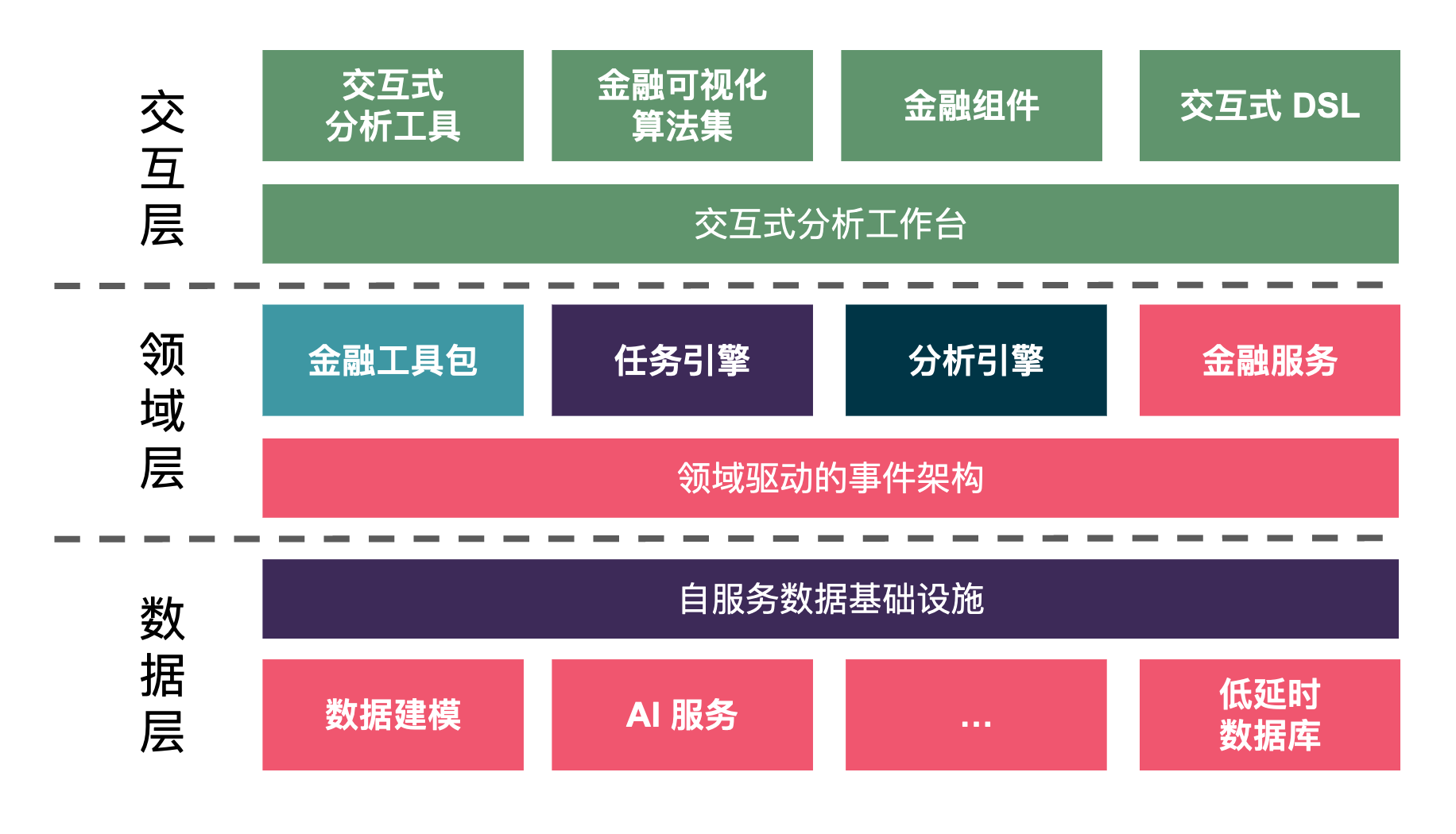
于是乎,在这个模式中,它主要由如下的三层所组件:
- 交互层 —— 组件丰富的可交互式分析工作台。
- 领域层 —— 持续丰富的金融服务与中间件平台。
- 数据层 ——自服务分布式数据基础设施。
当然了,为了实现上面的目标数据平台、服务组件化等等,一个都不可缺少。除此,更有意思的是这三层的每个层都是可扩展的:组件化、插件化等,诸如于 UI 层,可以通过插件化来快速实施。
交互层:组件丰富的可交互式分析工作台
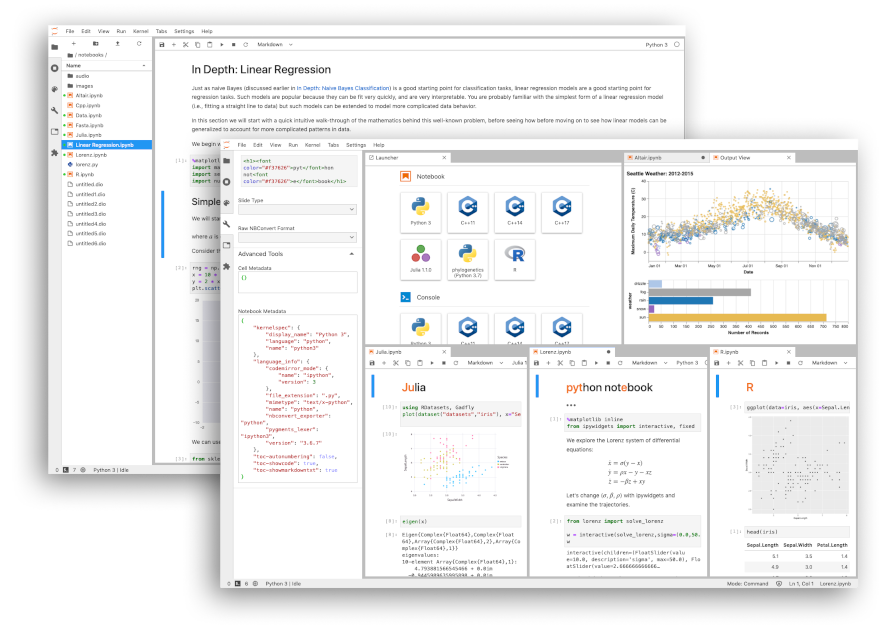
在这一层时,便是金融 Python 的核心交互所在,它需要提供这么一些能力。
- 可交互工作台。诸如于 Jupyter、Zeppelin 等工具提供这样的工作台能力。
- 交互式 DSL。与其他脚本语言相比,Python 语言具有非常好的交互性。并且作为一个开源的语言,也不会遇到 Slang 这一类的遗留基础设施的问题。
- 金融组件集。提供交互式分析和数据可视化组件,并封装这些组件,提供快速嵌入的能力。
- 金融可视化算法集。封装金融领域特有的数据算法。当然了,如何让构建的算法性能更高?也是一个非常有意思的问题。
Jupyter 已经成为了今天的可交互式分析代表性的工具,诸如于 Goldman Sachs 等金融科技公司也采用了这样的平台。值得一提的是,诸如于 Perspective 提供了一系列金融相关组件集,并内置了一个快速、内存高效的流式查询引擎,还基于 WebAssembly 和 Web Components 技术来提供高性能的前端组件,还有 Jupyter 等一系列的插件。而像 ExprTK 则能提供一个简单易用、易于集成且极其高效的运行时数学表达式解析器和评估引擎,也是一个非常不错的工具。
所以,对于这个工作台来说,在特定的场景下,它还需要具备这么三个属性:低延迟组件(流式数据)、高性能快速计算(WASM)、快速查询 DSL。
领域层:持续丰富的金融服务与中间件平台
从国内对于中台的喜爱来说,人们似乎喜欢把它称之为金融中台。但是,我更喜欢称之为领域层,毕竟面向的是金融与数据分析领域的,而且它还是一个领域驱动的事件架构。
我们需要围绕于交互层的交互指令,对数据进行一系列的操作。于是乎,我们关注于:
- 金融与数据处理工具包。诸如于经典的 NumPy、SciPy、Pandas 等,又或者是高盛提供的 GS Quant 便是一个非常不错的工具集。
- 金融服务。诸如于常见的风控系统等,我们还要考虑,如何将投资组合风险分析和保险的合规性检查、欺诈检测、自动化交易等问题集成到系统中。
- 计算引擎与任务调度。对于计算引擎来说,我们还得考虑对于 DAG 任务的支持,跟踪计算状态以及它们之间的依赖关系,允许完全和部分重新计算。
从系统的实现层面来说,其实我们应该关注的是:围绕 DAG 去实现任务编排,诸如于 Apache Airflow 便是一个非常不错的工具。
数据层:自服务分布式数据基础设施
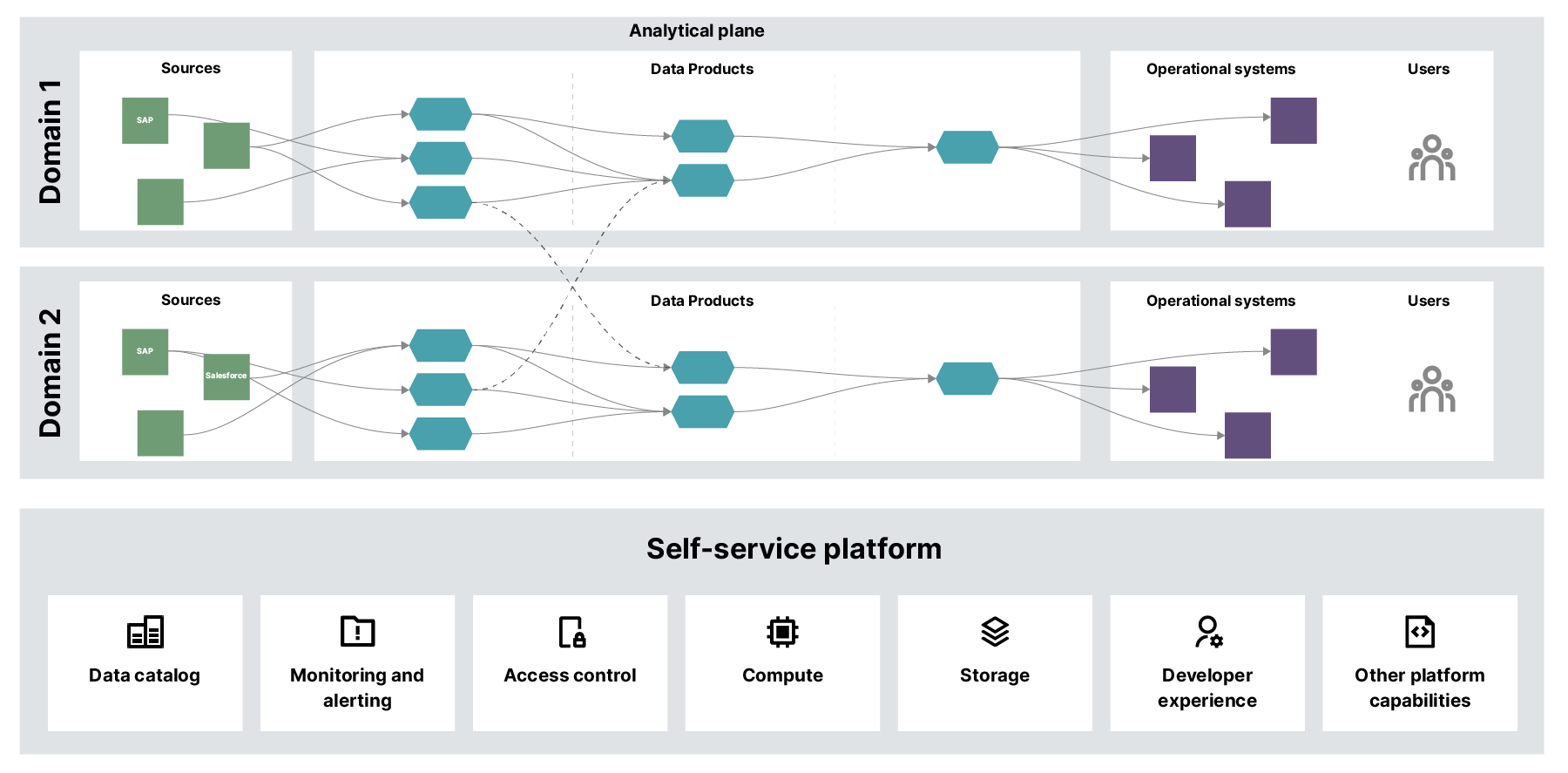
从某种意义上来说,这一层在今天可能会被称为 DATA AI,因为它们由 AI 和数据两层所构成
- 在数据侧,我们并不考虑使用 Python 来构建,主流的大数据相关的工具都围绕于 Java 语言所设计。从结果来看,就是构建一个数据湖,而与数据湖相比,构建 Dash Mesh 架构更适合这里的场景。
- 在 AI 侧,有大量的 Machine Learning 相关的工作,需要去训练模型,采用 CD4ML 来为机制学习构建持续学习。
所以,同样也是这么几个维度:
- 低延时数据库。与其他领域相比,接入低延时数据库是诸如高频交易等领域所需要的。
- 实时处理交易数据。则需要围绕于交易事件构建 Flink 集群,以及对应的集群处理机制。
- AI 服务。诸如于 NLP 对于各类文档、报表等进行自动化分析,以将这些非结构化的数据进行结构化。
在比较懒的情况下,采用诸如于 Trino(Presto )这一类的 SQL-On-Anything 查询引擎作为 wrapper 也是一个非常不错的解决方案。
问题
在细节上,我们还要考虑的是:
- 治理、风险管理和合规检查等等。
- 数据安全。对应数据的权限安全等。
- 混合云架构。
当然了,这些都可以算是基础设施。
类似用法
其它相似的模式,还有:
- 基于 Lambda 架构的数据应用分析。采用 Serverless 平台来快速部署应用和分析功能。
- 低代码金融服务平台。采用低代码的分析,在线构建应用,并实时部署。
- BI(Business Intelligence)分析工具。使用 BI 作为基础设施,将数据处理集成到 BI 中。
当然,这些都是 "传统" 的方式。
已知应用
- 高盛的 SecDB 及其 Slang。约 1.5 亿行 Slang 代码
- 摩根大通的 Athena。约 5 千万行 Python 代码
- 美银证券的 Quartz
- Beacon 平台
其它
参考资源:
或许您还需要下面的文章:
围观我的Github Idea墙, 也许,你会遇到心仪的项目
- 验证工程:从 Vibe 硬件编程 Loop 到自迭代验证
- 长程验证:AI Agent 长任务的收敛机制
- 从复杂编辑器到 Agent 工作台:Office 的 Cursor 时刻
- 注意力 Harness:多 Agent 时代如何守住人的注意力
- Agent 应该如何解决繁杂任务:从 /goal 到长时间运行
- 任务自适应 Harness:从 Trace 到多 Coding Agent 的协作记忆
- 从写清 Spec 到看懂功能:在 Session 历史中使用 Routa 重建需求全景
- Routa 桌面版发布:内建 Harness 工程的 AI Coding 研发协作工作台
- Harness Monitor:当多个 Agent 同时写代码时,如何看住质量
- Gate First:为你的 Agent Team 构建 Harness 防御体系
 Engineer, Consultant, Writer, Designer
Engineer, Consultant, Writer, Designer
ThoughtWorks 技术专家
工程师 / 咨询师 / 作家 / 设计学徒
开源深度爱好者
出版有《前端架构:从入门到微前端》、《自己动手设计物联网》、《全栈应用开发:精益实践》
联系我: h@phodal.com
微信公众号: 最新技术分享

- opensuse (10)
- django (41)
- arduino (10)
- thoughtworks (18)
- centos (9)
- nginx (18)
- java (10)
- SEO (9)
- iot (47)
- iot system (12)
- RESTful (23)
- refactor (17)
- python (47)
- mezzanine (15)
- test (11)
- design (16)
- linux (14)
- tdd (12)
- ruby (14)
- github (24)
- git (10)
- javascript (52)
- android (36)
- jquery (18)
- rework (13)
- markdown (10)
- nodejs (24)
- google (8)
- code (9)
- macos (9)
- node (11)
- think (8)
- beageek (8)
- underscore (14)
- ux (8)
- microservices (10)
- rethink (9)
- architecture (37)
- backbone (19)
- mustache (9)
- requirejs (11)
- CoAP (21)
- aws (10)
- dsl (9)
- ionic (25)
- Cordova (21)
- angular (16)
- react (14)
- ddd (9)
- summary (9)
- growth (10)
- frontend (14)
- react native (8)
- serverless (32)
- rust (9)
- llm (8)