博客反爬虫 策略一——根据User Agent
看了看Webmaster Tools的时候,发现我博客的Indexed一直在掉,搜索结果也开始被一些爬虫网站干掉时。。
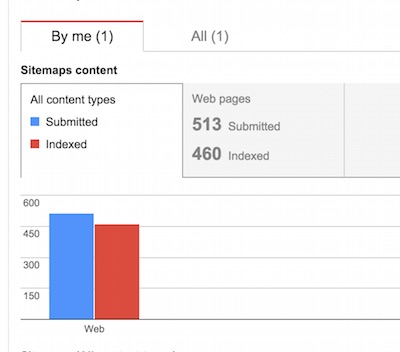
是时候反击了。当我意识到我的博客正在受到侵害的时候,让我们对爬虫宣战吧。
分析
于是再度拿来了goaccess 分析 nginx log。
| Visitors | % | Name |
|---|---|---|
| 58222 | 50.71% | Unknown |
| 21231 | 18.49% | Safari |
| 18422 | 16.04% | Chrome |
| 7049 | 6.14% | Crawlers |
至少有6%是Crawlers,没有办法确认50%的未知是什么情况,这些爬虫有:
- Googlebot
- bingbot
- Googlebot-Mobile
- Baiduspider
- YisouSpider
当然还有一些坏的爬虫:
- AhrefsBot
- Python-urllib/2.6
- MJ12bot/v1.4.5
- Slurp
先让我们干掉这些Bug。。。
用User Agent禁用爬虫
于是在网上找到了一些nginx的配置
# Forbid crawlers such as Scrapy
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
# Disable specify UA and empty UA access
if ($http_user_agent ~ "FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
# Forbid crawlers except GET|HEAD|POST method
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}顺手也把curl也禁用掉了,
curl -I -s www.phodal.com
HTTP/1.1 403 Forbidden
Server: mokcy/0.17.9
Date: Thu, 09 Apr 2015 14:22:42 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 169
Connection: keep-alive当User Agent是上面的爬虫时,返回403。如果是Google的Bot的话:
curl -I -s -A 'Googlebot' www.phodal.com
HTTP/1.1 200 OK
Server: mokcy/0.17.9
Content-Type: text/html; charset=utf-8
Connection: keep-alive
Vary: Accept-Encoding
Vary: Accept-Language, Cookie
Content-Language: en
X-UA-Compatible: IE=Edge,chrome=1
Date: Thu, 09 Apr 2015 14:39:11 GMT
X-Page-Speed: Powered By Phodal
Cache-Control: max-age=0, no-cache符合预期
其他
当然,这只是开始,我们还有其他工作要做~~、
附
下面是一个Apache的配置
<Directory "/var/www">
# Anti crawlers
SetEnvIfNoCase User-Agent ".*(^$|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms)" BADBOT
Deny from env=BADBOT
Order Allow,Deny
Allow from all
</Directory>或许您还需要下面的文章:
围观我的Github Idea墙, 也许,你会遇到心仪的项目
comment
- 验证工程:从 Vibe 硬件编程 Loop 到自迭代验证
- 长程验证:AI Agent 长任务的收敛机制
- 从复杂编辑器到 Agent 工作台:Office 的 Cursor 时刻
- 注意力 Harness:多 Agent 时代如何守住人的注意力
- Agent 应该如何解决繁杂任务:从 /goal 到长时间运行
- 任务自适应 Harness:从 Trace 到多 Coding Agent 的协作记忆
- 从写清 Spec 到看懂功能:在 Session 历史中使用 Routa 重建需求全景
- Routa 桌面版发布:内建 Harness 工程的 AI Coding 研发协作工作台
- Harness Monitor:当多个 Agent 同时写代码时,如何看住质量
- Gate First:为你的 Agent Team 构建 Harness 防御体系
 Engineer, Consultant, Writer, Designer
Engineer, Consultant, Writer, Designer
ThoughtWorks 技术专家
工程师 / 咨询师 / 作家 / 设计学徒
开源深度爱好者
出版有《前端架构:从入门到微前端》、《自己动手设计物联网》、《全栈应用开发:精益实践》
联系我: h@phodal.com
微信公众号: 最新技术分享

- opensuse (10)
- django (41)
- arduino (10)
- thoughtworks (18)
- centos (9)
- nginx (18)
- java (10)
- SEO (9)
- iot (47)
- iot system (12)
- RESTful (23)
- refactor (17)
- python (47)
- mezzanine (15)
- test (11)
- design (16)
- linux (14)
- tdd (12)
- ruby (14)
- github (24)
- git (10)
- javascript (52)
- android (36)
- jquery (18)
- rework (13)
- markdown (10)
- nodejs (24)
- google (8)
- code (9)
- macos (9)
- node (11)
- think (8)
- beageek (8)
- underscore (14)
- ux (8)
- microservices (10)
- rethink (9)
- architecture (37)
- backbone (19)
- mustache (9)
- requirejs (11)
- CoAP (21)
- aws (10)
- dsl (9)
- ionic (25)
- Cordova (21)
- angular (16)
- react (14)
- ddd (9)
- summary (9)
- growth (10)
- frontend (14)
- react native (8)
- serverless (32)
- rust (9)
- llm (8)