编辑-发布-开发分离:git作为NoSQL数据库
动态网页是下一个要解决的难题。我们从数据库中读取数据,再用动态去渲染出一个静态页面,并且缓存服务器来缓存这个页面。既然我们都可以用Varnish、Squid这样的软件来缓存页面——表明它们可以是静态的,为什么不考虑直接使用静态网页呢?
为了实现之前说到的编辑-发布-开发分离的CMS,我还是花了两天的时间打造了一个面向普通用户的编辑器。效果截图如下所示:
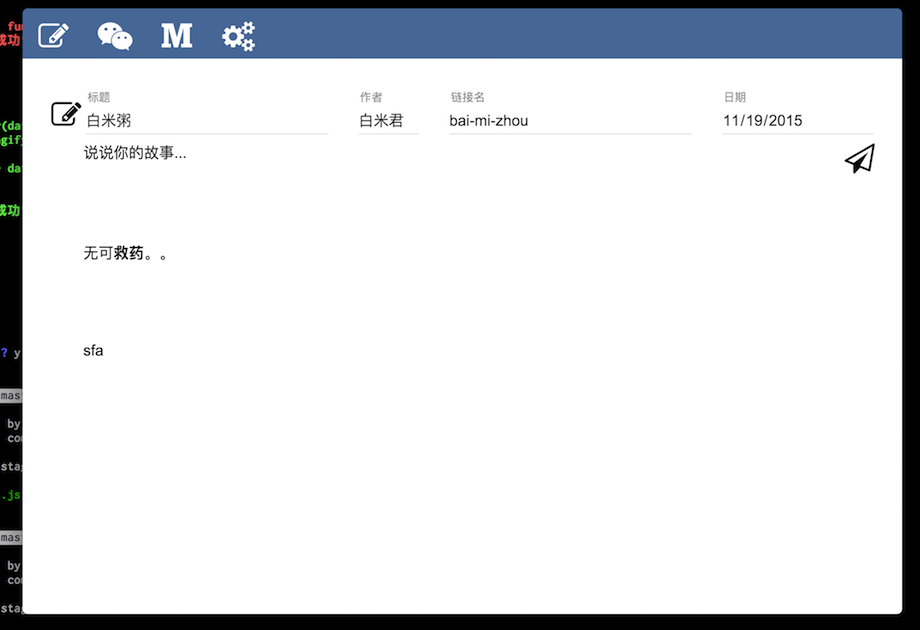
作为一个普通用户,这是一个很简单的软件。除了Electron + Node.js + React作了一个140M左右的软件,尽管打包完只有40M左右 ,但是还是会把用户吓跑的。不过作为一个快速构建的原型已经很不错了——构建速度很快、并且运行良好。
尽管这个界面看上去还是稍微复杂了一下,还在试着想办法将链接名和日期去掉——问题是为什么会有这两个东西?
从Schema到数据库
我们在我们数据库中定义好了Schema——对一个数据库的结构描述。在《编辑-发布-开发分离 》一文中我们说到了echeveria-content的一个数据文件如下所示:
{
"title": "白米粥",
"author": "白米粥",
"url": "baimizhou",
"date": "2015-10-21",
"description": "# Blog post \n > This is an example blog post \n Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. ",
"blogpost": "# Blog post \n > This is an example blog post \n Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. \n Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum."
}比起之前的直接生成静态页面这里的数据就是更有意思地一步了,我们从数据库读取数据就是为了生成一个JSON文件。何不直接以JSON的形式存储文件呢?
我们都定义了这每篇文章的基本元素:
- title
- author
- date
- description
- content
- url
即使我们使用NoSQL我们也很难逃离这种模式。我们定义这些数据,为了在使用的时候更方便。存储这些数据只是这个过程中的一部分,下部分就是取出这些数据并对他们进行过滤,取出我们需要的数据。
Web的骨架就是这么简单,当然APP也是如此。难的地方在于存储怎样的数据,返回怎样的数据。不同的网站存储着不同的数据,如淘宝存储的是商品的信息,Google存储着各种网站的数据——人们需要不同的方式去存储这些数据,为了更好地存储衍生了更多的数据存储方案——于是有了GFS、Haystack等等。运营型网站想尽办法为最后一公里努力着,成长型的网站一直在想着怎样更好的返回数据,从更好的用户体验到机器学习。而数据则是这个过程中不变的东西。
尽管,我已经想了很多办法去尽可能减少元素——在最开始的版本里只有标题和内容。然而为了满足我们在数据库中定义的结构,不得不造出来这么多对于一般用户不友好的字段。如链接名是为了存储的文件名而存在的,即这个链接名在最后会变成文件名:
repo.write('master', 'contents/' + data.url + '.json', stringifyData, 'Robot: add article ' + data.title, options, function (err, data) {
if(data.commit){
that.setState({message: "上传成功" + JSON.stringify(data)});
that.refs.snackbar.show();
that.setState({
sending: 0
});
}
});然后,上面的数据就会变成一个对象存储到“数据库”中。
今天 ,仍然有很多人用Word、Excel来存储数据。因为对于他们来说,这些软件更为直接,他们简单地操作一下就可以对数据进行排序、筛选。数据以怎样的形式存储并不重要,重要的是他们都以文件的形式存储着。
git作为NoSQL数据库
在控制台中运行一下 man git你会得到下面的结果:
这个答案看起来很有意思——不过这看上去似乎无关主题。
不同的数据库会以不同的形式存储到文件中去。blob是git中最为基本的存储单位,我们的每个content都是一个blob。redis可以以rdb文件的形式存储到文件系统中。完成一个CMS,我们并不需要那么多的查询功能。
这些上千年的组织机构,只想让人们知道他们想要说的东西。
我们使用NoSQL是因为:
- 不使用关系模型
- 在集群中运行良好
- 开源
- 无模式
- 数据交换格式
我想其中只有两点对于我来说是比较重要的集群与数据格式。但是集群和数据格式都不是我们要考虑的问题。。。
我们也不存在数据格式的问题、开源的问题,什么问题都没有。。除了,我们之前说到的查询——但是这是可以解决的问题,我们甚至可以返回不同的历史版本的。在这一点上git做得很好,他不会像WordPress那样存储多个版本。
git + JSON文件
JSON文件 + Nginx就可以变成这样一个合理的API,甚至是运行方式。我们可以对其进行增、删、改、查,尽管就当前来说查需要一个额外的软件来执行,但是为了实现一个用得比较少的功能,而去花费大把的时间可能就是在浪费。
git的“API”提供了丰富的增、删、改功能——你需要commit就可以了。我们所要做的就是:
- git commit
- git push
或许您还需要下面的文章:
围观我的Github Idea墙, 也许,你会遇到心仪的项目
- 设计流动摩擦:AI 原生团队的核心能力
- Piece:将 Coding Agent 的局部构建反馈提速 10x
- 验证工程:从 Vibe 硬件编程 Loop 到自迭代验证
- 长程验证:AI Agent 长任务的收敛机制
- 从复杂编辑器到 Agent 工作台:Office 的 Cursor 时刻
- 注意力 Harness:多 Agent 时代如何守住人的注意力
- Agent 应该如何解决繁杂任务:从 /goal 到长时间运行
- 任务自适应 Harness:从 Trace 到多 Coding Agent 的协作记忆
- 从写清 Spec 到看懂功能:在 Session 历史中使用 Routa 重建需求全景
- Routa 桌面版发布:内建 Harness 工程的 AI Coding 研发协作工作台
 Engineer, Consultant, Writer, Designer
Engineer, Consultant, Writer, Designer
ThoughtWorks 技术专家
工程师 / 咨询师 / 作家 / 设计学徒
开源深度爱好者
出版有《前端架构:从入门到微前端》、《自己动手设计物联网》、《全栈应用开发:精益实践》
联系我: h@phodal.com
微信公众号: 最新技术分享

- opensuse (10)
- django (41)
- arduino (10)
- thoughtworks (18)
- centos (9)
- nginx (18)
- java (10)
- SEO (9)
- iot (47)
- iot system (12)
- RESTful (23)
- refactor (17)
- python (47)
- mezzanine (15)
- test (11)
- design (16)
- linux (14)
- tdd (12)
- ruby (14)
- github (24)
- git (10)
- javascript (52)
- android (36)
- jquery (18)
- rework (13)
- markdown (10)
- nodejs (24)
- google (8)
- code (9)
- macos (9)
- node (11)
- think (8)
- beageek (8)
- underscore (14)
- ux (8)
- microservices (10)
- rethink (9)
- architecture (37)
- backbone (19)
- mustache (9)
- requirejs (11)
- CoAP (21)
- aws (10)
- dsl (9)
- ionic (25)
- Cordova (21)
- angular (16)
- react (14)
- ddd (9)
- summary (9)
- growth (10)
- frontend (14)
- react native (8)
- serverless (32)
- rust (9)
- llm (8)