DSL 三步曲一 —— Geng
上个月将关注点放在了DSL上面,也就是DSL三步曲的第一步,一个简单的自然语言时间解析。
Geng
让我们先从测试用例看起
it('should correctly convert time', function () {
expect(Geng.parser('子时在今天是几点').convert()).toEqual({from: '23', to: '1'});
expect(Geng.parser('丑时在今天是几点').convert()).toEqual({from: '1', to: '3'});
});我们要实现的是这样的一个解析自然语言的软件,主要会有三个步骤
- 将自然语言分成词
- 接着简单的匹配
- 简单的对应关系
因为我是特别懒的一个人,所以在了解需要用什么算法,了解算法的原理之后。我会
分词
找了很多分词算法,发现我并不需要考虑效率的问题,毕竟对于分词来说最重要的是字典,最后用了Trie树来实现。
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
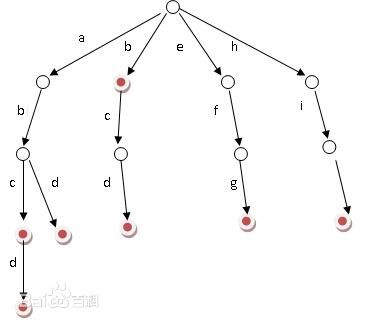
于是,子时在今天是几点会变成子时,今天,几点,接着把它丢到
词法分析器
接着需要有一个Lexer。先看看测试:
it('should return input type', function () {
_lexer.addRule(/[a-f\d]+/i, function () {
return 'HEX';
});
_lexer.setInput('aa0000');
var result = _lexer.lex();
expect(result).toBe('HEX');
});我们就是对应于相应的匹配给一定的结果,最后来进行处理。
Bayes
原来是有Bayes的设计,用于区分古代和现代,但是后来想想好像没有多大的必要。不过,还是找了经典Bayes的库。
it('should correctly return correspond result', function () {
_bayes.learn('amazing, awesome movie!! Yeah!! Oh boy.', 'positive');
_bayes.learn('Sweet, this is incredibly, amazing, perfect, great!!', 'positive');
_bayes.learn('terrible, shitty thing. Damn. Sucks!!', 'negative');
var result = _bayes.categorize('awesome, cool, amazing!! Yay.');
expect(result).toBe('positive');
});虽然很扯淡,但是免强可以用的。
其他
出现的问题: 由于一开始设计的目标过于宏大,导致无法如期完成。。
源码: [https://github.com/phodal/geng](https://github.com/phodal/geng)
或许您还需要下面的文章:
围观我的Github Idea墙, 也许,你会遇到心仪的项目
comment
- 验证工程:从 Vibe 硬件编程 Loop 到自迭代验证
- 长程验证:AI Agent 长任务的收敛机制
- 从复杂编辑器到 Agent 工作台:Office 的 Cursor 时刻
- 注意力 Harness:多 Agent 时代如何守住人的注意力
- Agent 应该如何解决繁杂任务:从 /goal 到长时间运行
- 任务自适应 Harness:从 Trace 到多 Coding Agent 的协作记忆
- 从写清 Spec 到看懂功能:在 Session 历史中使用 Routa 重建需求全景
- Routa 桌面版发布:内建 Harness 工程的 AI Coding 研发协作工作台
- Harness Monitor:当多个 Agent 同时写代码时,如何看住质量
- Gate First:为你的 Agent Team 构建 Harness 防御体系
 Engineer, Consultant, Writer, Designer
Engineer, Consultant, Writer, Designer
ThoughtWorks 技术专家
工程师 / 咨询师 / 作家 / 设计学徒
开源深度爱好者
出版有《前端架构:从入门到微前端》、《自己动手设计物联网》、《全栈应用开发:精益实践》
联系我: h@phodal.com
微信公众号: 最新技术分享

- opensuse (10)
- django (41)
- arduino (10)
- thoughtworks (18)
- centos (9)
- nginx (18)
- java (10)
- SEO (9)
- iot (47)
- iot system (12)
- RESTful (23)
- refactor (17)
- python (47)
- mezzanine (15)
- test (11)
- design (16)
- linux (14)
- tdd (12)
- ruby (14)
- github (24)
- git (10)
- javascript (52)
- android (36)
- jquery (18)
- rework (13)
- markdown (10)
- nodejs (24)
- google (8)
- code (9)
- macos (9)
- node (11)
- think (8)
- beageek (8)
- underscore (14)
- ux (8)
- microservices (10)
- rethink (9)
- architecture (37)
- backbone (19)
- mustache (9)
- requirejs (11)
- CoAP (21)
- aws (10)
- dsl (9)
- ionic (25)
- Cordova (21)
- angular (16)
- react (14)
- ddd (9)
- summary (9)
- growth (10)
- frontend (14)
- react native (8)
- serverless (32)
- rust (9)
- llm (8)