DDM: 一个简洁的前端领域模型库
在上一篇文章《前后端分离之领域模型的思考》中,我们介绍了在前端开发中所遇到的一个问题。即:
一个模型多个上下文的问题
对于我们的几个不同业务情景下,我们只使用同一个后台API的情形。如下图所示:
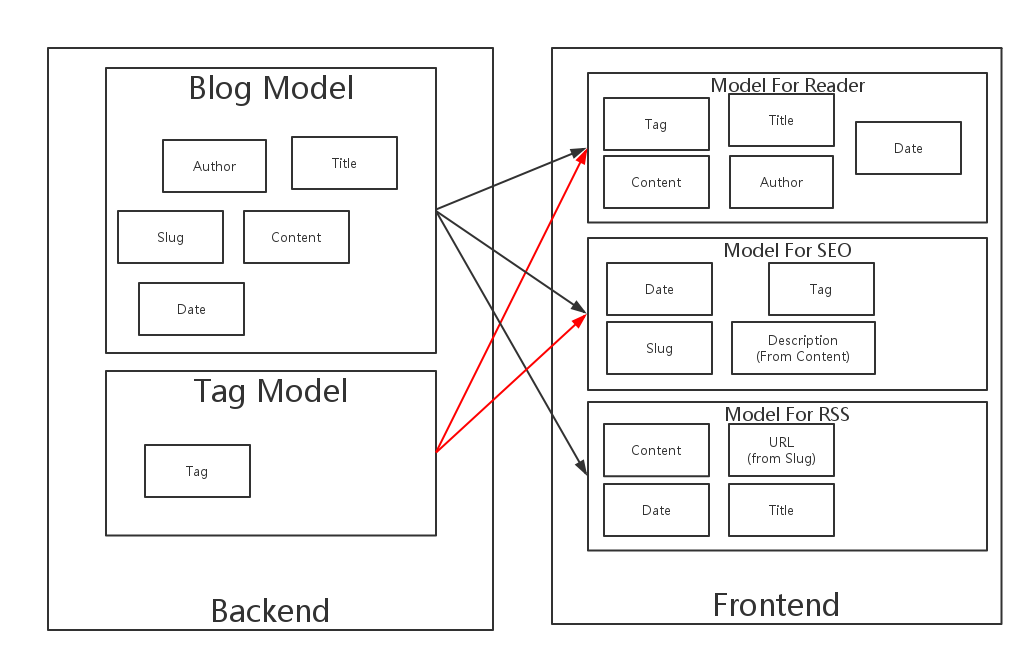
在我们的Blog Model里,我们有Author、Title、Slug、Content、Data几个字段。
而在我们使用的时候,我们需要依据这个模型应用到不同的场景下:
- 面向读者的Model,只有
Tag、Title、Author、Date、Content五个字段。 - 面向SEO时,只有
Tag、Title、Date、基于Content的Description四个字段。 - 面向RSS时,则有
Title、Author、Date、Content、Slug五个字段。
如果我们使用的是同一个模型,那么我们就很难做到分离上下文。并且在三种不同的场景下,Blog Model的含义都是不一样的:
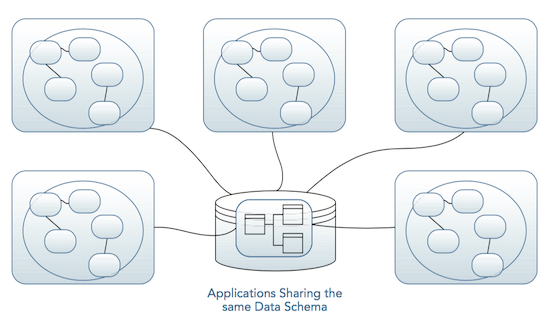
于是,我们就需要想办法去区分不同的模型——这在后台来说是一件很容易的事:
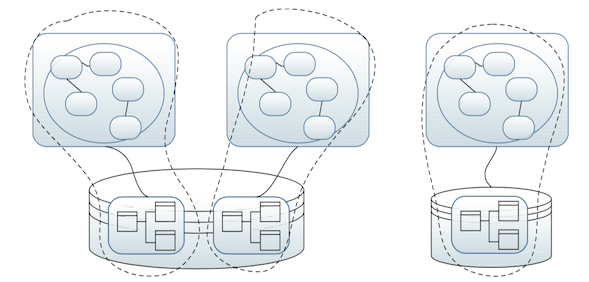
但是在前台谁想这样做?在这其中使用复杂的OO思想?
所以,我们有了DDM。
DDM
我也想不起来为什么是Domain Double Model,大概是Frontend算是一个Model,后台算是一个Model。反正这个库就是叫这个名字了。
对于前台来说,一种理想的方式就是直接Clone一个Blog对象,然后从中获取所需要的字段了。
ddm.get(['Date', 'Tag', 'Content', 'Title', 'Author'])
.from(orignBlog)
.to(ReaderBlog);在一些博客里,如我的Django驱动的博客,Tag是属于另外一个API,就需要另外ADD
ddm.get(['Date', 'Content', 'Title', 'Author'])
.from(orignBlog)
.add('Tag', Tag)
.to(ReaderBlog);对于一些复杂的例子,我们就需要一个简单的Handle函数,如:
function handler(content) {
return content[0];
}
ddm.get(['Date', 'Tag', 'Slug', 'Content'])
.from(originObject)
.handle("Content", handler)
.to(newObject);突然发现这里少了一个例子是:把Content变成Description,然后减少字符。。。
就这么简单和任性.
GitHub: https://github.com/phodal/ddm
或许您还需要下面的文章:
围观我的Github Idea墙, 也许,你会遇到心仪的项目
- Harness Engineering 的下一步:Fitness Function 定义 AI Agent 的完成条件
- 当 Kanban 不再管理人:Routa Kanban 如何管理 Agent Team
- Harness Engineering 的防御视角:从 Codex Security 看 AI 生成代码的治理
- AI Coding Fluency:从工具使用到人机协作的软件工程
- Harness Engineering 实践指南:落地探索的三大原则
- 2026 年,万物皆 Coding Agent 的平台工程(A2A / ACP / MCP / Skill)
- Agent Team 实践与架构设计:在约束下构建可演进的一个人开发团队
- 从 AutoDev 到 Routa:开放生态下的新一代多 Agent 编排实践
- ACP 协议 + 多 AI 编程智能体:企业研发的新生产力平台
- A2A vs ACP 协议对比分析
 Engineer, Consultant, Writer, Designer
Engineer, Consultant, Writer, Designer
ThoughtWorks 技术专家
工程师 / 咨询师 / 作家 / 设计学徒
开源深度爱好者
出版有《前端架构:从入门到微前端》、《自己动手设计物联网》、《全栈应用开发:精益实践》
联系我: h@phodal.com
微信公众号: 最新技术分享

- opensuse (10)
- django (41)
- arduino (10)
- thoughtworks (18)
- centos (9)
- nginx (18)
- java (10)
- SEO (9)
- iot (47)
- iot system (12)
- RESTful (23)
- refactor (17)
- python (47)
- mezzanine (15)
- test (11)
- design (16)
- linux (14)
- tdd (12)
- ruby (14)
- github (24)
- git (10)
- javascript (52)
- android (36)
- jquery (18)
- rework (13)
- markdown (10)
- nodejs (24)
- google (8)
- code (9)
- macos (9)
- node (11)
- think (8)
- beageek (8)
- underscore (14)
- ux (8)
- microservices (10)
- rethink (9)
- architecture (37)
- backbone (19)
- mustache (9)
- requirejs (11)
- CoAP (21)
- aws (10)
- dsl (9)
- ionic (25)
- Cordova (21)
- angular (16)
- react (14)
- ddd (9)
- summary (9)
- growth (10)
- frontend (14)
- react native (8)
- serverless (32)
- rust (9)
- llm (8)