【架构拾集】前后端分离演进:不能微服务,那就 BFF 隔离
现有的绝大多数软件系统,都将在未来某一刻成为遗留系统,只是时间跨度不一样。好的系统,拥有好的设计,并在其生命周期里不断地演进。但是没有一个设计能抵抗住时间,以及业务带来的变更。
技术远景
或许你在我之前的文章里已经了解了 BFF 是什么,又或许你已经从其它渠道了解到这方面的知识。如果没有的话,那么让我再简单地介绍一下:什么是 BFF?
BFF
BFF,即 Backends For Frontends (服务于前端的后端),也就是服务器设计 API 时会考虑前端的使用,并在服务端直接进行业务逻辑的处理。
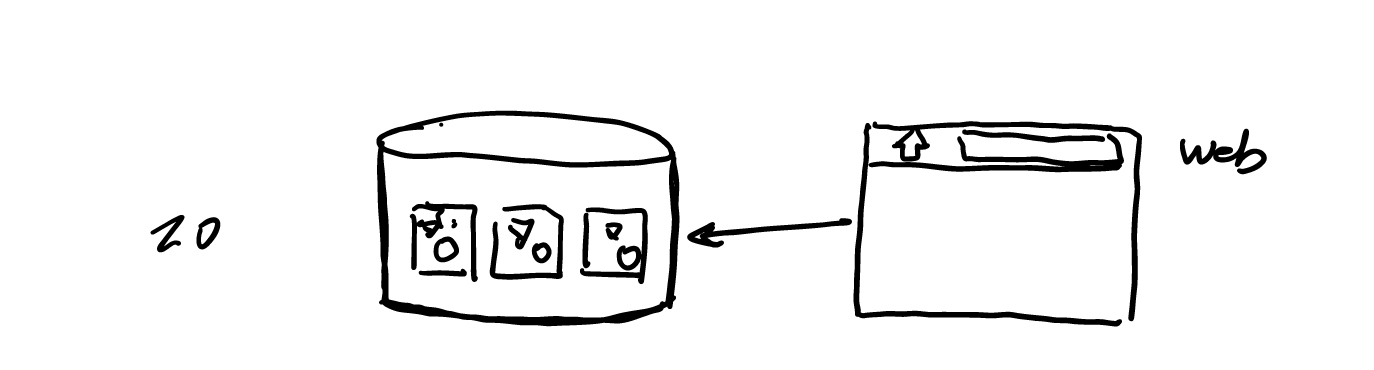
系统看上去是如何的简洁,由于只是尝试线上的业务也不多。然后,十多年前我们开始应对移动设备,适配出了一层 API 层:
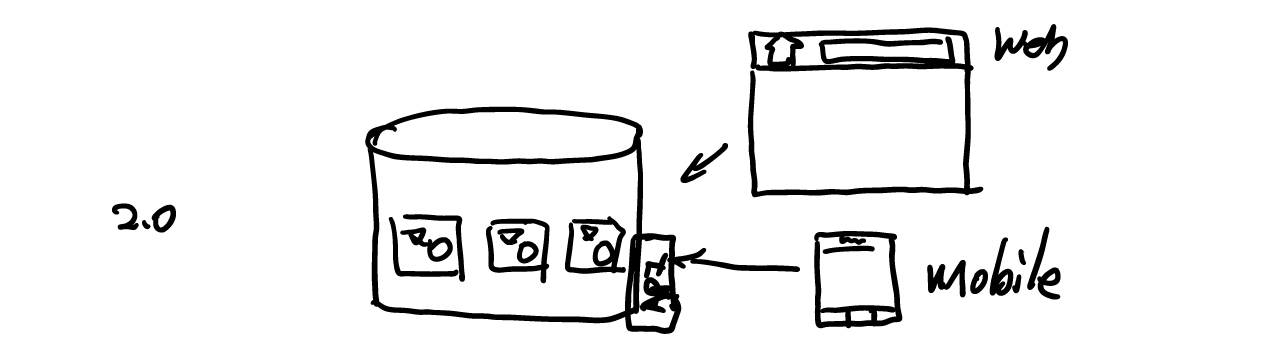
这一层适配出来的 API,并不是精心设计的。它可能只是一一将数据库的 Scheme:
CREATE TABLE contents (
`id` int(11) DEFAULT NULL auto_increment PRIMARY KEY,
`type` varchar(255),
`title` varchar(255),
`author` varchar(255),
`body` text,
http://architecture.phodal.com/.
) TYPE=MyISAM;在代码中将这些对象转化成 JSON,然后提供给前端使用。而随着 Web 应用的交互变得越来越复杂,PC 端也开始大量地使用 API,而不是后台渲染:
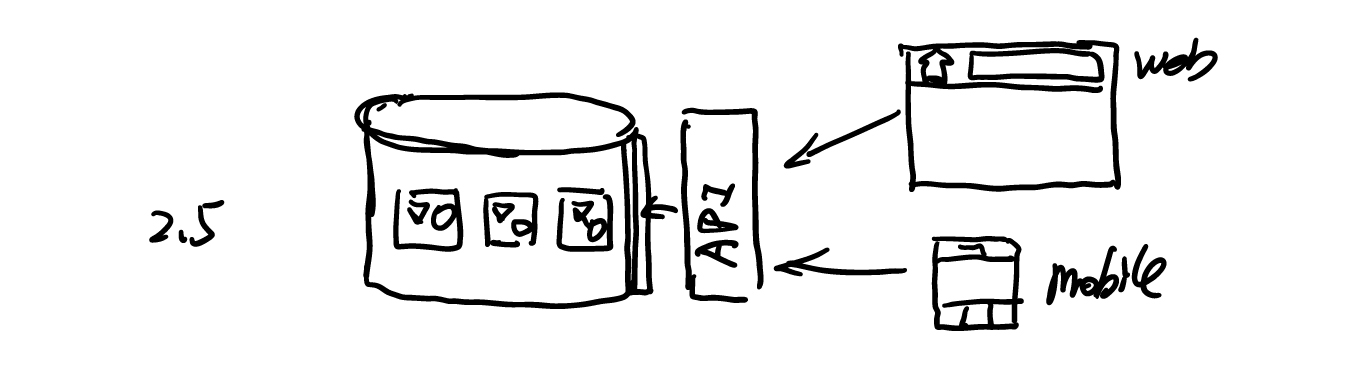
先前后台直接将数据库中的值返回给前端,而每当值发生一些变化时,需要 Android、iOS、Web 做出修改。与此同时,当我们需要对一个字符串进行处理,如限定 140 个字符的时候,我们需要在每一个客户端(Android、iOS、Web)分别实现一遍,这样的代价显然相当的大。于是,我们就需要 BFF 作为中间件。在这个中间件上我们将做一些业务逻辑处理:
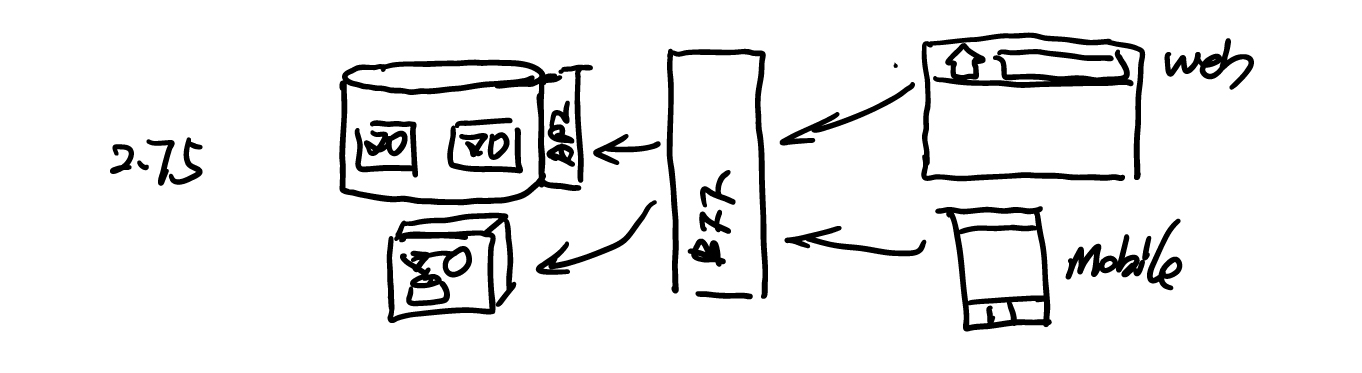
而当我们有了这一层 BFF 层时,我们就不需要考虑系统后端的迁移。后端发生的变化都可以在 BFF 层上,做一些相应的修改:
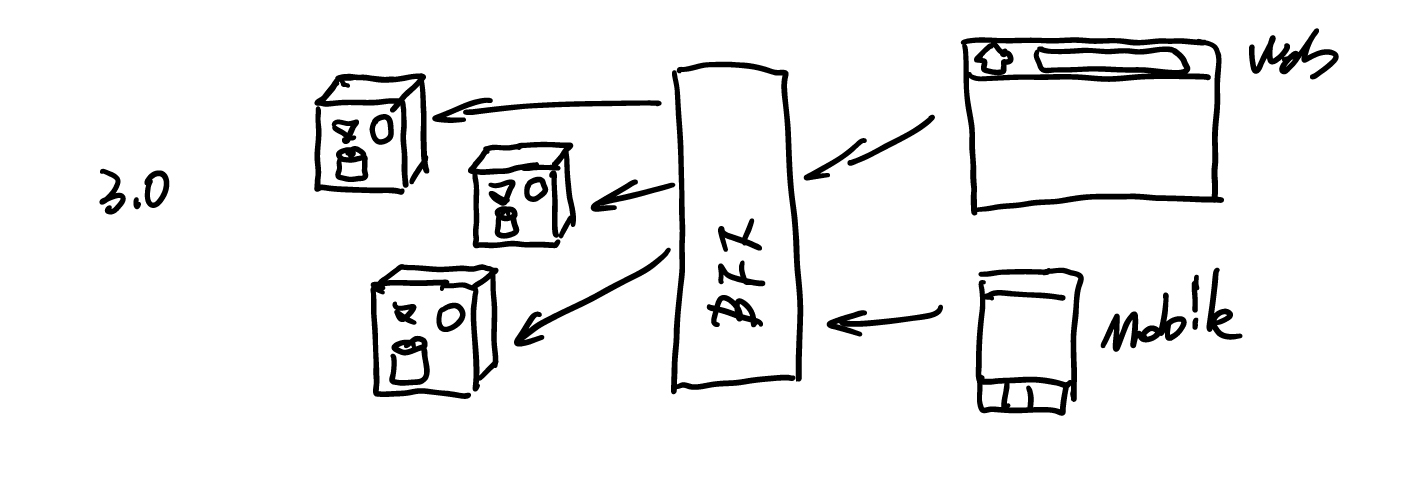
直至,我们将系统的前端和后端重构到新的架构上,前端与后端之间相互不像影响。
测试策略
考虑到系统的兼容性,
再一次回到测试金字塔上,由于使用的是新系统、新的语言,旧的单元测试必然是不可用的。而服务测试和 UI 测试则是可以兼容的,这主要取决于系统的设计。
服务测试
对于后台而言,我们仍然是从系统中读取数据库,最后显示的结果应该保持一致——只是可能是不同的数据库,又或者读取的方式从 ODBC 变成了 JDBC。对于前端开发者而言,后台并没有发生任何的变化——当然在没有 BFF 隔离层的情况下,可能就是多个请求变成了一个请求。
如我们在上述系统中遇到的情况是,生成的 URL 和页面的标题应该是不变的,因此我们需要编写测试来对应 URL 和标题来测试:
title,url
Phodal's Idea实战指南,https://github.com/phodal/ideabook
一步步搭建物联网系统,https://github.com/phodal/designiot
GitHub 漫游指南,https://github.com/phodal/github-roam
RePractise,https://github.com/phodal/repractise
Growth: 全栈增长工程师指南,https://github.com/phodal/growth-ebook
Growth: 全栈增长工程师实战,https://github.com/phodal/growth-in-action
我的职业是前端工程师,https://github.com/phodal/fe
写给软件工程师看的硬件编程指南,https://github.com/phodal/make先编写旧有系统的 URL 测试,然后一一验证内容是否一致即可。
行为测试
为了保证新旧系统的兼容,我们有必要进行自动化 UI 测试,以此来保证新系统的正常。
而如果我们先前的 UI 测试是使用 BDD 架构编写的,那么我们便可以继续沿用之前的行为。同时,我们只需要修改一下测试脚本的实现:
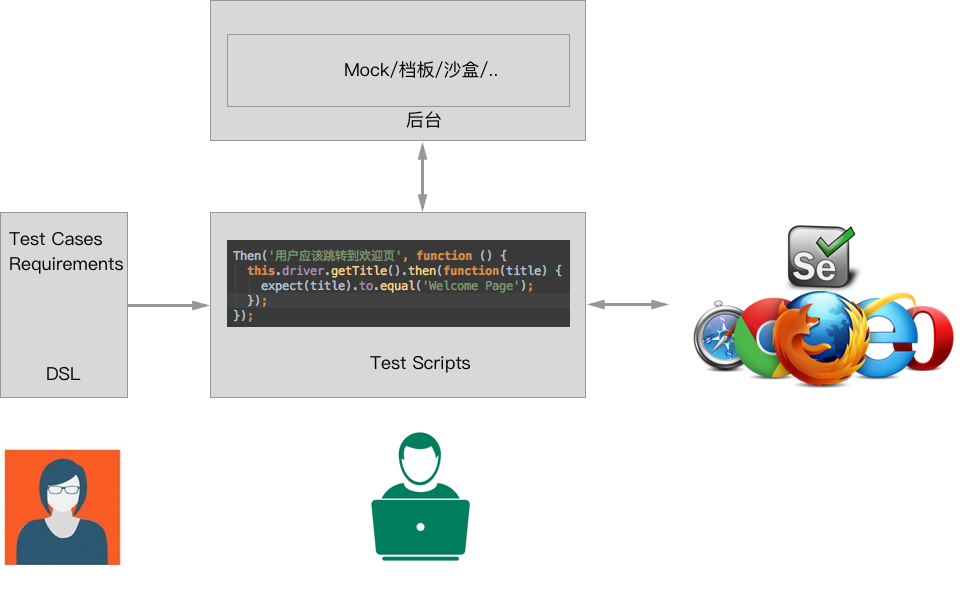
以 Cucumber 为例:
# language: zh-CN
功能: 失败的登录
场景大纲: 失败的登录
假设 当我在网站的首页
当 输入用户名 <用户名>
当 输入密码 <密码>
当 提交登录信息
那么 页面应该返回 "Error Page"
例子:
|用户名 |密码 |
|'Jan1' |'password'|
|'Jan2' |'password'|业务不变的情况下,那么这些行为也是不变的,由于变化的是底层的实现。如之前的登录按钮的 id 是 login,现在这个按钮的 id 可能变成了 new_login。new_login 绝对是一个取得很差的名字,下次重构的时候可能仍是 new_login。
或者 ThoughtWorks 出品的 Gauge:
失败的登录
===
|用户名 |密码 |
|--------|--------|
|Jan1 |password|
|Jan2 |password|
失败的登录
-----------
* 当我在网站的首页
* 输入用户名 <用户名>
* 输入密码 <密码>
* 提交登录信息
* 页面应该返回 "Error Page"案例
两年前,我工作在一个房地产搜索网站上。它是一个相关久远的系统,以至于我们在修 bug 的时候可以看到 10 年前的注释。当时,我们采用了采用绞杀者模式来对系统进行重写,即在遗留系统外面增加新的功能做成微服务方式。
由于这是一个已经在线上的系统,因此在重写的过程中,仍然要保证旧的功能不被破坏。在旧有的系统中拥有一个维护不了的搜索引擎,为了替换这个搜索引擎,我们创建了一层 API 服务层——在一层 API 里,我们适配了旧的搜索引擎,并开发了新搜索引擎的适配层。在今天看来,它算是一种 BFF 的实现,并且这种迁移方式相当的可靠。
结论
尽管如此,要直接从旧的系统直接采用 BFF 也不是一件容易的事。我们需要隔离好不同环境,并做好大量的技术准备。
或许您还需要下面的文章:
围观我的Github Idea墙, 也许,你会遇到心仪的项目
- Piece:将 Coding Agent 的局部构建反馈提速 10x
- 验证工程:从 Vibe 硬件编程 Loop 到自迭代验证
- 长程验证:AI Agent 长任务的收敛机制
- 从复杂编辑器到 Agent 工作台:Office 的 Cursor 时刻
- 注意力 Harness:多 Agent 时代如何守住人的注意力
- Agent 应该如何解决繁杂任务:从 /goal 到长时间运行
- 任务自适应 Harness:从 Trace 到多 Coding Agent 的协作记忆
- 从写清 Spec 到看懂功能:在 Session 历史中使用 Routa 重建需求全景
- Routa 桌面版发布:内建 Harness 工程的 AI Coding 研发协作工作台
- Harness Monitor:当多个 Agent 同时写代码时,如何看住质量
 Engineer, Consultant, Writer, Designer
Engineer, Consultant, Writer, Designer
ThoughtWorks 技术专家
工程师 / 咨询师 / 作家 / 设计学徒
开源深度爱好者
出版有《前端架构:从入门到微前端》、《自己动手设计物联网》、《全栈应用开发:精益实践》
联系我: h@phodal.com
微信公众号: 最新技术分享

- opensuse (10)
- django (41)
- arduino (10)
- thoughtworks (18)
- centos (9)
- nginx (18)
- java (10)
- SEO (9)
- iot (47)
- iot system (12)
- RESTful (23)
- refactor (17)
- python (47)
- mezzanine (15)
- test (11)
- design (16)
- linux (14)
- tdd (12)
- ruby (14)
- github (24)
- git (10)
- javascript (52)
- android (36)
- jquery (18)
- rework (13)
- markdown (10)
- nodejs (24)
- google (8)
- code (9)
- macos (9)
- node (11)
- think (8)
- beageek (8)
- underscore (14)
- ux (8)
- microservices (10)
- rethink (9)
- architecture (37)
- backbone (19)
- mustache (9)
- requirejs (11)
- CoAP (21)
- aws (10)
- dsl (9)
- ionic (25)
- Cordova (21)
- angular (16)
- react (14)
- ddd (9)
- summary (9)
- growth (10)
- frontend (14)
- react native (8)
- serverless (32)
- rust (9)
- llm (8)